
NEWS • The Cult of DNA-centricity
The CULT OF DNA-CENTRICITY
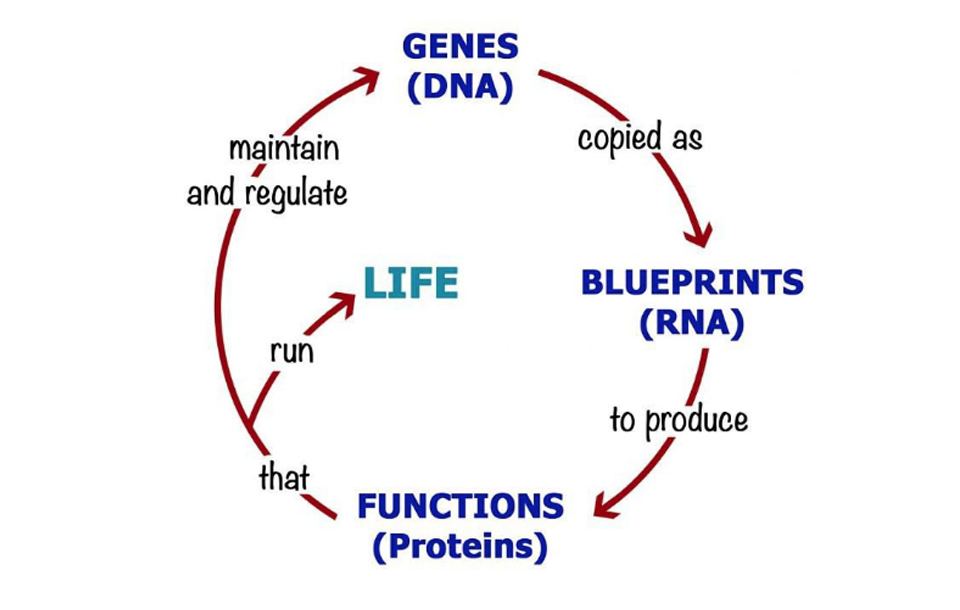
Courtesy of Prof Miroslav Radman, MedILS "The Central Dogma of molecular biology is usually linear: DNA makes RNA makes Protein - but proteins make DNA, completing the Circle of Life"
Understanding the role of DNA in biology is arguably the single most important scientific advance of the 20th century. It provides the molecular basis of inheritance, and understanding how the genetic code is translated into proteins providing a whole new insight into the workings of the human body.
The fundamental unit of inheritance is the gene, a stretch of DNA that contains the information needed to make one protein. It soon became clear that errors in the DNA sequence of a single gene caused a vast array of inherited diseases, such as cystic fibrosis and Duchene Muscular Dystrophy.
Through the latter decades of the 20th Century, advances in the methodology for sequencing DNA accelerated the pace of discovery, culminating in the publication of the first complete human genome sequence (that is, the sequence of all the DNA in a cell) at the turn of the millennium. This new molecular genetics identified literally thousands of genetic mutations that caused human diseases.
Even today, the ripples of the genomics revolution are still playing out. We are seeing the first gene therapies approved as medicines, where individuals with a mutant copy of a particular gene are provided with additional normal copies, allowing the correct protein now to be made, in many cases with impressive benefits.
In haemophilia A, which causes bleeding, mutations in the DNA of the gene that encodes a protein called Factor VIII important for normal clotting. Once the genetic basis for this deficiency was understood in the 1980s, scientists at Genentech were able to clone the normal copy of the gene and insert it into cultured cells so they could make Factor VIII, which could be purified and injected into patients with haemophilia A, effectively curing them.
The obvious next step (to put the normal copy of the gene into the patient directly), however, has taken thirty more years, as the serious technical challenges of introducing new DNA sequences into a living person were gradually overcome. But today it is a reality, and several companies are racing to the FDA for approval of a “once and done” treatment, giving patients a normal copy of the gene so they can, for the first time, produce their own Factor VIII.
Even that is not the end of the journey. With the discovery of CRISPR, biologists can edit faulty genes directly. The next generation of tools promise DNA editing as easy as installing new software.
In the face of such impressive progress, it is not surprising that the role of DNA in biology has come to be seen as central. Reading its sequence identifies the causes of disease, and correcting any sequence errors cures the patient. Even the language of molecular biology cements this DNA-centric vision, captured in the simple phrase “DNA makes RNA makes Protein”, the Central Dogma of molecular biology. Genetic medicines, then, offer a route to a disease-free utopia, if only we can overcome remaining technical hurdles to allow us to edit the DNA at will.
But is this DNA-centric narrative accurate?
To an extent – but with some important, and often over-looked, limitations. First and foremost, this DNA-centric framework that has been so successful in uncovering the mechanisms behind so-called “rare diseases” (that is, early-onset inherited disorders caused a defect in one or two genes) does not seem to generalize very well to the later-onset degenerative diseases that affect almost all of us as we get older. The breathtaking progress towards cures for “rare diseases” is in stark contrast to the almost complete lack of progress towards treatments, let alone cures, for diseases like type 2 diabetes, autoimmune disorders and neurodegenerative conditions such as Alzheimer’s Disease.
As the genetic basis of “rare diseases” was uncovered early in the genomics revolution, the prevalent assumption was that the later-onset age-related diseases were caused in essentially the same way, except that the number of genes involved was larger (maybe ten or even a hundred), perhaps in two or three interacting biological pathways. Genome-wide Association Studies, a statistical framework for identifying altered DNA sequences associated with a biological trait, such as a disease, were run and everyone waited with bated breath for insights into the causes of these age-related degenerative diseases. And almost two decades later we are still waiting.
It must be obvious, today, that the answer is not coming from this line of investigation. But so strong is the cult of DNA-centricity that most scientists seem unwilling to challenge the fundamental assumption that the cause of these late onset diseases must lie somewhere in the genome.
The second limitation is also obvious: DNA, like data, cannot by itself do anything. The data on your computer is powerless without apps to interpret it, screens and speakers to communicate it, keyboards and touchscreens to interact with it. Similarly, the DNA sequence information (although it resides in a physical object, the DNA molecule, just as computer data resides on a hard disk) is powerless and ethereal until it is translated into proteins that can perform functions.
And those functions critically include maintaining the DNA sequence (errors creep in every time it is copied, and proteins must repair those errors quickly before they become permanently incorporated into the sequence), copying the DNA at each cell division, as well as the act of translating DNA sequence in more proteins. The Central Dogma is incomplete: DNA makes RNA makes Protein makes DNA. Watson & Crick’s formulation puts DNA at the top of a hierarchy, when in reality it is an equal partner in the circle of life.
Subtle as it seems, this distinction matters. All diseases (and indeed all biological traits) are caused by differences in your proteins – just as haemophilia A is caused by a deficiency of the Factor VIII protein. It just so happens that the difference in the Factor VIII protein levels was in turn caused by a mutation in the DNA sequence that encoded it.
But protein sequence is not ONLY determined by the gene sequence. Proteins are not made of diamond, unchanging and inviolate over centuries – they are made of amino acid molecules that are susceptible to change, both deliberate and accidental damage. Biologists are very familiar with deliberate changes to proteins (such as phosphorylation), but the accidental damage, though maybe just as frequent, is more or less ignored. Amino acids can become modified in a dizzying array of chemical reactions, from oxidation in air, to reaction with glucose to form so-called Advanced Glycation End-products (or, appropriately, AGEs – which accumulate with age).
Such protein instability remains, relative to the study of DNA, a back-water of research only because of the pervasive belief that DNA sequence lies at the top of the hierarchy. After all, if a protein becomes damaged, so what? It will be replaced in a while with a shiny new copy, freshly translated from the DNA plans. As long as the underlying DNA sequence remains healthy, damaged old proteins will just get replaced with perfect new ones.
And for the most part, that assumption turns out to be perfectly correct. It is inconceivable that you could get a trait or disease due to a protein getting damaged. For a start, evolution has selected protein sequences that are relatively robust, and beyond that we have a range of mechanisms for clearing out old, damaged proteins. Diseases, like haemophilia, caused by loss of function of protein, can really only come from alterations in the DNA sequence.
What about the opposite problem, though? What if damage to a protein increased its stability? Now something very different happens. Even with a perfectly normal gene sequence turning out perfect new copies of the protein, because the lifespan of the damaged version is longer, it will very gradually accumulate over time. Eventually the amount of the damaged protein, with altered function, may get high enough that it changes the function of the cell or tissue. What we observe now is a trait or disease caused by a toxic gain of function rather than from a loss of function.
At a stroke, this explains why age-related diseases, such as Alzheimer’s Disease, diabetes or autoimmunity often take decades to develop (even though your genome sequence has been the same since the day you were conceived): the insidious accumulation of the damaged protein may be very slow indeed. It also explains why GWAS studies fail to find the principal cause of the disease – because the answer never lay in the DNA sequence.
Ageing, and age-related degenerative diseases, are caused, then, by protein damage rather than by DNA damage. In a DNA-centric scientific community, this statement, put forward by Professor Miroslav Radman from the Mediterranean Institute of Life Sciences (MedILS) in Split, Croatia, is tantamount to heresy. A generation of biologists have grown up with Central Dogma imprinted on their brains, and struggle to contemplate disease mechanisms that do not originate in the DNA sequence.
None of this should come as a surprise – most of what makes you a unique individual is coded in the three-dimensional pattern of cells and proteins in your body, and not in your DNA. Your memories, for example, have no basis in DNA – they live in the neuronal connections of your brain. Your wrinkles, should you have any, are not genome-encoded but a consequence of accumulating long-lived variants of altered skin proteins. You are a product of your genes, but also of your environmental history leaving a lasting imprint on your proteins.
Once the Central Dogma has been expanded into a circle, the inevitable importance of both genomic and proteomic damage in ageing becomes obvious. But there is work to do, convincing a skeptical world that the promise of gene therapies, whether conventional somatic gene transfer or next-generation gene editing strategies, have limits to what they can hope to achieve.
But on a more positive note, it opens up a whole new universe to discover – the domain of proteome damage. By looking for which long-lived damaged protein variants (which Professor Radman calls Hyper-Stable Danger Variants) accumulate in age-related diseases, we can uncover the true causes of diseases, like Alzheimer’s Disease and type 2 diabetes, unlocking new drug discovery efforts. The proteome instability revolution promises even greater medical advances than those that followed the genomic revolution.
And all that is holding us back is the cult of DNA-centricity.